Towards Topic-Guided Conversational Recommender System 论文阅读
- Abstract
- 1 Introduction
- 2 Related Work
- 2.1 Conversation System
- 2.2 Conversational Recommender System
- 2.3 Dataset for Conversational Recommendation
- 3 Dataset Construction
- 3.1 Collecting Movies for Recommendation
- 3.2 Creating Topic Threads
- 3.3 Generating the Conversation
- 3.4 The TG-ReDial Dataset
- 4 Our Approach
- 4.1 Problem Formulation
- 4.2 Recommendation Module
- 4.3 Dialog Module
- 5 Experiments
- 5.1 Evaluation on Item Recommendation
- 5.2 Evaluation on Topic Prediction
- 5.3 Evaluation on Response Generation
- 6 Conclusion
文章信息:

原文链接:https://arxiv.org/abs/2010.04125
源码:https://github.com/RUCAIBox/TG-ReDial
Abstract
对话推荐系统(CRS)旨在通过交互式对话向用户推荐高质量的项目。为了开发有效的CRS,高质量数据集的支持是必不可少的。现有的CRS数据集主要关注用户的即时请求,而缺乏对推荐场景的主动引导。在本文中,我们贡献了一个新的CRS数据集,名为TG-ReDial(通过主题引导的对话进行推荐)。我们的数据集具有两个主要特点。首先,它结合了主题线索,以确保向推荐场景的自然语义转换。其次,它是以半自动方式创建的,因此人类注释更加合理和可控。基于TG-ReDial,我们提出了主题引导的对话推荐任务,并提出了一种有效的方法来解决这一任务。广泛的实验已经证明了我们的方法在三个子任务上的有效性,即主题预测、项目推荐和响应生成。TG-ReDial可在以下链接获取:https://github.com/RUCAIBox/TG-ReDial。
1 Introduction

最近,对话推荐系统(CRS)(Chen等人,2019;Sun和Zhang,2018;Li等人,2018;Zhang等人,2018b;Liao等人,2019)已成为一个新兴的研究课题,旨在通过自然语言对话为用户提供高质量的推荐。通常,CRS由推荐组件和对话组件组成,分别负责提供合适的推荐和生成恰当的响应。为了开发有效的CRS,高质量的数据集对于学习模型参数至关重要。现有的CRS数据集大致可以分为两类,即基于属性的用户模拟(Sun和Zhang,2018;Lei等人,2020;Zhang等人,2018b)和基于闲聊的目标完成(Li等人,2018;Chen等人,2019;Liu等人,2020)。
这些数据集通常假设用户在与系统交互时有明确、即时的需求。它们缺乏从非推荐场景到所需推荐场景的主动引导(或过渡)。实际上,根据对话上下文自然触发推荐变得越来越重要(Tang等人,2019;Kang等人,2019)。这个问题在DuRecDial数据集(Liu等人,2020)中得到了一定程度的探讨。DuRecDial通过构建目标序列来描述目标规划过程。然而,它主要关注对话子任务(例如,非推荐、推荐和问答)的类型切换或覆盖。明确的语义过渡,即如何引导到推荐,尚未在DuRecDial数据集中得到充分研究或讨论。此外,大多数现有的CRS数据集(Liu等人,2020;Li等人,2018)主要依赖人类标注者来创建用户画像或生成对话。由于生成的对话主要反映了标注者的特征(例如,兴趣)或预定义的身份,因此很难通过有限数量的人类标注者捕捉到现实应用中的丰富、复杂的案例。
为了解决上述问题,我们构建了一个新的CRS数据集,名为通过主题引导的对话进行推荐(TG-ReDial)。该数据集包含10,000段在电影领域的两方对话,对话双方分别为寻求者和推荐者。我们的数据集有两个新的特点。首先,我们明确创建了一个主题线索,以引导每段对话的整个内容流程。从非推荐主题开始,主题线索通过一系列演变主题自然地将用户引导到推荐场景。我们的数据集通过闲聊对话强制实现了向推荐的自然过渡。其次,我们的数据集是以半自动方式创建的,涉及合理且可控的人类标注努力。关键思想是将对话中的用户身份与来自一个流行电影评论网站的真实用户对齐。通过这种方式,推荐的电影、创建的主题线索和推荐理由都是基于真实数据挖掘或生成的。人类标注者的主要任务是在必要时修订、润色或重写对话数据。因此,我们不再依赖人类标注者来创建个性化的用户画像,如先前的研究(Li等人,2018;Liu等人,2020),使我们的对话数据更接近现实案例。图1展示了我们TG-ReDial数据集的一个示例。
基于TG-ReDial数据集,我们研究了一个新的主题引导的对话推荐任务,该任务可以分解为三个子任务,即项目推荐、主题预测和响应生成。主题预测的目的是创建引导最终推荐的主题线索;项目推荐提供符合用户需求的合适项目;响应生成则生成自然语言的适当回复。在我们的方法中,推荐模块利用历史交互和对话文本来推导准确的用户偏好,分别通过顺序推荐模型SASRec(Kang和McAuley,2018)和预训练语言模型BERT(Devlin等人,2019)进行建模。对话模块包括一个主题预测模型和一个响应生成模型。主题预测模型整合了三种有用的数据(即历史发言、历史主题和用户画像)来预测下一个主题。响应生成模型基于GPT-2(Radford等人,2019)实现,用于生成引导用户或提供有说服力的推荐的回应。为了验证我们方法的有效性,我们在TG-ReDial数据集上进行了广泛的实验,将我们的方法与竞争基线模型进行比较。我们的主要贡献总结如下:
(1)我们发布了一个新的对话推荐系统数据集TG-ReDial。它强调了引导最终推荐的自然主题过渡。我们的数据集是以半自动方式创建的,因此人类标注更加合理和可控。
(2)基于TG-ReDial,我们提出了主题引导的对话推荐任务,包括项目推荐、主题预测和响应生成。我们进一步开发了一种有效的解决方案,基于Transformer及其变体BERT和GPT-2利用多种数据信号。
2 Related Work
2.1 Conversation System
对话系统(Shang等,2015;Li等,2016;Dhingra等,2017)研究如何在给定多轮上下文话语的情况下生成适当的回应。现有工作可分为任务导向系统(Dhingra等,2017;Young等,2007)和闲聊系统(Li等,2016;Shang等,2015;Zhou等,2019)。任务导向系统旨在完成特定目标(如订票),而闲聊系统则提供通用对话。与我们的工作相关,话题信息在对话系统研究领域引起了广泛关注(Xing等,2017;Tang等,2019;Xu等,2020),因为它能够增强生成对话的语义。早期研究(Xing等,2017;Lian等,2019)侧重于引导下一轮回应的话题,而近期研究(Tang等,2019;Xu等,2020)则开始强调整个对话中的多轮话题引导过程。例如,关键词转移(Tang等,2019)和知识图谱(Xu等,2020)被引入以改进话题引导的对话系统。
2.2 Conversational Recommender System
对话推荐系统(Conversational Recommender System, CRS)(Chen等,2019;Sun和Zhang,2018;Li等,2018)旨在通过与用户的对话提供高质量的推荐。通常,它由两个部分组成:一个对话组件用于与用户交互,另一个推荐组件用于根据用户偏好选择推荐项目。早期的对话推荐系统(Christakopoulou等,2016;Sun和Zhang,2018;Zhou等,2020c)主要通过询问用户对预定义槽位的偏好来进行推荐。近年来,一些研究(Li等,2018;Chen等,2019;Liu等,2020)开始通过自然语言对话与用户交互,强调流畅的回应生成和精准的推荐。此外,后续研究(Chen等,2019;Kang等,2019;Zhou等,2020b)引入了知识图谱或强化学习,通过增强的用户模型或交互机制来提升对话推荐系统的性能。
2.3 Dataset for Conversational Recommendation
为了促进对话推荐系统的研究,近年来已发布了多个数据集(Li等,2018;Kang等,2019;Liu等,2020;Lei等,2020)。其中,Facebookrec(Dodge等,2016)和EAR(Lei等,2020)是基于经典推荐数据集通过自然语言模板构建的合成对话数据集。ReDial(Li等,2018)、GoReDial(Kang等,2019)和DuRecDial(Liu等,2020)则是通过人工标注创建的,具有预定义目标(如项目推荐和目标规划)。这些目标导向的数据集结合了闲聊和任务导向(推荐任务)对话的元素。与这些数据集相比,我们的数据集强调话题引导的过程,自然地将会话引导至对话推荐系统的推荐场景中。值得注意的是,DuRecDial数据集(Liu等,2020)与TG-ReDial数据集类似,都利用目标序列来引导对话。然而,DuRecDial的目标序列由多种任务类型组成(例如推荐、问答等)。相比之下,TG-ReDial利用话题线索来表征内容流的演变,更容易融入开放域对话中。另一个显著区别是,DuRecDial依赖人工标注生成用户相关数据(如用户画像和话语),而TG-ReDial主要从电影评论网站挖掘合适的信息,更贴近真实场景。
3 Dataset Construction
借鉴(Sun和Zhang,2018;Li等,2018)的研究,我们采用了一种两方设置的对话推荐系统,其中用户和聊天机器人分别扮演信息寻求者和推荐者的角色。我们期望信息寻求者与推荐者之间的对话从非推荐场景开始。推荐者主动引导对话进入目标话题,然后根据寻求者的兴趣进行合适的推荐。
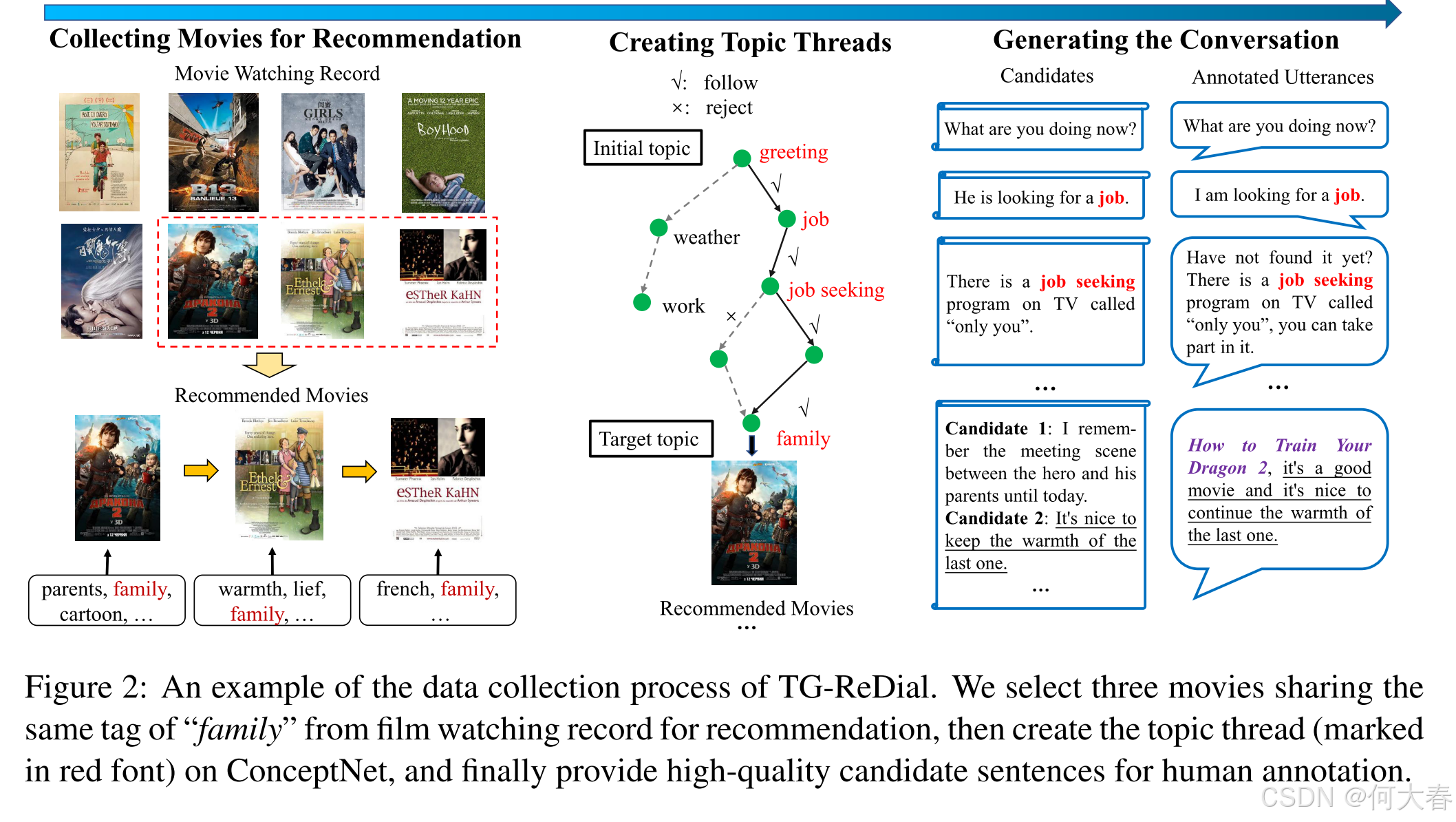
与以往的研究不同,我们以半自动化的方式构建了数据集。我们利用了中国热门电影评论网站豆瓣电影的真实数据记录。我们将每次对话与豆瓣电影的真实用户关联起来,从而可以结合用户的观看记录(喜欢和不喜欢)进行推荐。对于推荐的电影,我们创建了一个从先前话题演变到电影目标话题的话题线索。最后,人工标注者将根据用户画像和检索到的与电影相关的高质量候选内容生成合适的推荐回复。图2展示了构建过程的示例。
接下来,我们首先描述TG-ReDial数据集的构建过程,然后展示该数据集的详细统计信息。
](https://i-blog.csdnimg.cn/direct/7aada2e788294eccbd2d736c8867a74a.png)
3.1 Collecting Movies for Recommendation
为了模拟真实的推荐场景,我们首先收集了豆瓣上真实用户的观看记录以用于推荐。为了使推荐与话题相关,我们为每部电影附加了若干有意义的标签(例如类型、导演和主演)。我们保留了豆瓣电影中电影的原始标签,并进一步挖掘其评论以提取高频关键词,然后手动选择合适的标签。每部电影的标签数量设置为1到38个。整个观看序列被分割成若干连贯的子序列,其中确保电影至少共享一个共同标签。我们删除了不连贯的子序列。每个保留的子序列对应一次独特的对话,每个用户平均参与四到五次对话。给定一个用户,我们根据其对电影的评分标记接受/拒绝状态(接受:五星评分≥4;拒绝:五星评分≤2)。与之前的研究(Li等,2018;Liu等,2020)相比,一个主要区别是我们重用了带有评分偏好的现有观看记录(涵盖喜欢和不喜欢的电影),使生成的对话更贴近真实情况。
3.2 Creating Topic Threads
给定一次对话中的电影,我们通过话题标签以有序的方式将它们连接起来。每次对话的初始话题设置为问候语,目标话题则是下一部推荐电影的选定标签。为了创建话题线索,我们从初始话题开始,遍历常识知识图谱ConceptNet(Speer等,2017)。通过深度优先搜索(DFS)算法识别的最短话题路径被视为话题线索。我们多次重复上述过程,直到所有推荐电影都能通过话题线索连接起来。
为了增强信息寻求者的个性化特征,借鉴(Zhang等,2018a)的研究,我们生成了用户画像以更好地控制对话质量。我们首先从原始网站收集用户画像、自我描述及其评论文本中的关键词,然后利用47个手写模板生成句子来描述用户画像。通过用户画像,我们可以在生成话题线索时捕捉两种选项,即跟随和拒绝。在每一步中,跟随选项会将当前话题纳入话题线索,而拒绝选项则会考虑另一个话题进行扩展。选择依据是话题关键词是否出现在提取的画像关键词中。对于不在关键词中的话题,我们以0.5的概率拒绝扩展该话题。这种采样方式增加了对话数据的灵活性和多样性。
3.3 Generating the Conversation
在获得话题线索和推荐电影后,我们请众包工作者完成对话。每次对话从闲聊话语开始,根据话题线索演变,并在目标话题上提供推荐。尽管上述信息(即电影序列、话题线索和用户画像)已经高度概括了对话的框架,但在有限的人工标注者数量下进行数据标注仍然具有挑战性。受MultiWOZ(Budzianowski等,2018)的启发,我们提出了一种基于开放域对话语料库豆瓣(Wu等,2017)和爬取的电影评论的候选驱动标注方法,分别帮助生成与话题和推荐相关的话语。
给定一个话题线索,我们需要为其中的每个话题生成一句话语。给定一个话题,我们首先从豆瓣语料库中随机检索20条包含该话题的话语。然后,我们利用基于RNN的匹配模型(Lowe等,2015)计算它们与上一条话语的相关性,并选择最相关的句子作为候选话语。在这一步骤中,人工标注者的作用是修改检索到的候选话语,以确保整个对话的语义一致性。
对于目标话题,我们需要生成一个有说服力的推荐理由。回想一下,用户实际上已经观看了这部电影并发表了相关评论。我们利用目标话题作为查询,通过极端嵌入相似性(Liu等,2016a)检索出最相关的三条评论句子。标注者将从这三条候选句子中选择,并根据对话上下文在必要时进行修改或重写。
我们的众包工作者来自一家专业的数据标注公司。每条话语都分配给一名标注者(标注)和一名检查员(检查)。每位标注者都需要仔细阅读用户画像并浏览原始网站上的详细信息。为了保证人工生成数据的质量,我们进一步利用两个自动指标来识别低质量案例以进行重新标注。具体来说,我们计算Distinct指标(Li等,2016)以过滤具有较小Distinct值的低信息量对话;我们还计算给定候选话语与人工标注话语之间的BLEU分数(Papineni等,2002),然后过滤几乎没有修改的对话。这些不良案例将被重新标注,直到通过自动评估为止。
3.4 The TG-ReDial Dataset

TG-ReDial的详细统计数据如表1所示。TG-ReDial包含来自1,482名用户的129,392条话语。我们的数据集以话题引导的方式构建,包含更多信息丰富的句子。平均而言,每次对话有7.9个话题,每条话语包含19.0个单词,这些数字均大于现有对话推荐系统数据集(Li等,2018;Liu等,2020;Kang等,2019)的相应数值。此外,平均每位用户有10条画像句子和202.7条观看记录。
我们数据集的一个主要特点是通过话题线索组织对话,使得从闲聊到推荐的过渡更加自然。这样的数据集特别有助于将推荐组件集成到通用聊天机器人中,因为我们的主题很容易与开放域对话对齐。此外,我们将对话与唯一的用户身份相关联,使其更贴近现实情况。特别是,我们可以获取对话中用户的画像和观看历史。据我们所知,大多数现有数据集(Li等,2018;Liu等,2020)主要关注对话推荐系统的冷启动场景,而对话推荐系统利用现有用户的历史交互数据也同样重要。我们的数据集为利用历史交互数据训练对话推荐算法提供了可能性。由于我们的数据集中每个用户参与了多次对话,研究其他个性化任务也是可行的。
需要注意的是,为了保护用户隐私,我们仅采样了具有大量观看记录的用户。对于派生的用户数据(例如画像或观看记录),我们进行了匿名化处理并添加了随机修改(例如删除、替换或删除)。我们还要求检索到的评论句子必须通过改写生成。最后,我们要求人工标注者手动追踪数据集中用户身份与相应用户数据的对应关系。我们不包含最终数据集中可识别用户的数据。
4 Our Approach
在本节中,我们首先形式化定义了话题引导的对话推荐任务。然后,我们介绍了针对该任务的解决方案。
4.1 Problem Formulation
给定用户 u u u,我们假设她与一个画像 P u P_u Pu(一组与u感兴趣的话题相关的描述性句子)和一个历史交互序列 I u I_u Iu(u按时间顺序交互过的项目序列)相关联。每次对话由一系列话语组成,表示为 d = { s k } k = 1 n d=\{s_k\}_{k=1}^n d={sk}k=1n,其中 s k s_k sk是第 k k k轮的话语。我们以话题引导的方式考虑对话推荐系统,每条话语 s k s_k sk与一个话题 t k t_k tk相关联。当 t k t_k tk是目标话题时,系统将触发对项目 i k i_k ik的推荐,并提供有说服力的理由。
基于这些符号,话题引导的对话推荐任务定义为:给定用户画像 P u P_u Pu、用户交互序列 I u I_u Iu、历史话语 { s 1 , … , s k − 1 } \{s_1,\ldots,s_{k-1}\} {s1,…,sk−1}以及相应的话题序列 { t 1 , … , t k − 1 } \{t_1,\ldots,t_{k-1}\} {t1,…,tk−1},我们的目标是(1)预测下一个话题 t k t_k tk以到达目标话题,或(2)推荐电影 i k i_k ik,最后(3)生成关于该话题的适当回应 s k s_k sk或带有说服力的理由。这三个子任务分别称为话题预测、项目推荐和回应生成。
4.2 Recommendation Module
推荐模块的目标是根据对话上下文预测用户喜欢的项目。关键点是如何推导出有效的用户表示以进行推荐。我们为此任务考虑两种数据信号。特别地,我们利用预训练的语言模型BERT(Devlin等,2019)对历史话语 { s 1 , … , s k − 1 } \{s_1,\ldots,s_{k-1}\} {s1,…,sk−1}进行编码,并使用自注意力序列推荐模型SASRec(Kang和McAuley,2018)对用户交互序列 I u I_u Iu进行编码。
用户 u u u的表示 v u v_u vu如下获得:

其中 v u ( 1 ) \boldsymbol{v}_u^{(1)} vu(1)(从BERT获得)和 v u ( 2 ) \boldsymbol{v}_u^{(2)} vu(2)(从SASRec获得)分别是表示历史话语和交互序列的嵌入。给定用户表示,我们可以计算从项目集中向用户 u u u推荐项目 i i i的概率:

其中 e i e_i ei是项目 i i i的学习项目嵌入。我们利用公式2对所有项目进行排序,并选择概率最大的项目进行推荐。
4.3 Dialog Module
对话模块旨在为用户(寻求者)生成适当的回应,以进行话题引导或项目推荐。我们通过特定模型实现这两个目的。
Topic Prediction Model.
它预测下一个话题,引导用户u向目标话题发展。我们主要利用文本数据进行话题预测,并实现了三种不同的基于BERT的编码器,即对话-BERT、话题-BERT和画像-BERT,分别用于编码历史话语、历史话题序列和用户画像。对于每个BERT变体,我们简单地将所有可用的文本数据和目标话题(用[SEP]标记分隔)连接起来。目标话题的引入是为了增强话题语义。基于获得的表示,我们通过以下公式计算话题 t t t作为下一个话题的概率:

其中 e t e_t et是话题 t t t的学习嵌入, r ( 1 ) \boldsymbol{r}^{(1)} r(1)、 r ( 2 ) \boldsymbol{r}^{(2)} r(2)和 r ( 3 ) \boldsymbol{r}^{(3)} r(3)分别是历史话语、话题和用户画像的嵌入,分别从对话-BERT、话题-BERT和画像-BERT获得。我们利用公式[3]对所有话题进行排序,并选择概率最大的话题。
Response Generation Model.
它旨在为话题引导的对话生成适当的回应。我们利用预训练的文本生成模型GPT-2(Radford等,2019)进行回应生成。GPT-2利用堆叠的掩码多头自注意力层,通过通用语言模型(Radford等,2019;Devlin等,2019)在大量网络文本数据上进行训练。我们在此模型中考虑两种情况。对于非推荐情况,我们根据预测的话题生成回应,并将 t k t_k tk与历史话语 { s 1 , … , s k − 1 } \{s_1,\ldots,s_{k-1}\} {s1,…,sk−1}(用[SEP]标记分隔)连接起来。对于推荐情况,我们根据推荐的项目生成有说服力的理由,并将推荐的电影 i k i_k ik与历史话语 { s 1 , … , s k − 1 } \{s_1,\ldots,s_{k-1}\} {s1,…,sk−1}连接起来。对于这两种情况,我们可以将输入统一为一个长序列,该序列将被编码并输入GPT-2进行解码。
5 Experiments
我们在TG-ReDial数据集上评估所提出的方法,该数据集按8:1:1的比例分为训练集、验证集和测试集。对于每次对话,我们从第一条话语开始,依次通过模型生成回复话语或推荐。我们对三个子任务进行评估,即项目推荐、话题预测和回应生成。
5.1 Evaluation on Item Recommendation
在本小节中,我们进行了一系列实验,以验证我们提出的模型在推荐任务中的有效性。借鉴(Kang和McAuley,2018;Liu等,2016b)的研究,我们采用NDCG@k和MRR@k(k = 10, 50)作为评估指标,对所有可能的项目进行排序。
Baselines.
我们考虑以下基线模型进行性能比较:(1)Popularity根据交互次数衡量项目的流行度进行排序。(2)ReDial(Li等,2018)专门为对话推荐系统提出,利用自动编码器进行推荐。(3)KBRD(Chen等,2019)是最先进的对话推荐系统模型,使用知识图谱增强上下文项目或实体的语义以进行推荐。(4)GRU4Rec(Liu等,2016b)应用GRU对用户交互历史进行建模,不使用对话数据。(5)SASRec(Kang和McAuley,2018)采用Transformer架构对用户交互历史进行编码,不使用对话数据。(6)TextCNN(Kim,2014)采用基于CNN的模型从上下文话语中提取文本特征以进行推荐。(7)BERT(Devlin等,2019)是一种预训练语言模型,直接对连接的历史话语进行编码。
Result and Analysis.
表2展示了不同方法在推荐任务中的表现。可以看出,Popularity的表现优于ReDial但不如KBRD。ReDial和KBRD利用历史话语中的项目进行推荐。此外,KBRD结合了外部知识图谱以增强项目的表示。其次,SASRec的表现优于GRU4Rec和两个对话推荐系统模型(即KBRD和ReDial)。这表明自注意力架构特别适合对交互历史进行建模。此外,基于文本的TextCNN(即TextCNN和BERT)表现优于其他基线模型,这表明利用历史话语进行推荐是有用的。在这两个基于文本的模型中,BERT的表现优于TextCNN,因为它采用了更强大的架构并利用大规模数据进行训练。最后,我们提出的模型显著优于所有基线模型。我们的模型能够同时利用历史话语和交互序列,结合了BERT和SASRec的优点。

5.2 Evaluation on Topic Prediction
我们继续评估我们方法在话题预测任务中的表现。借鉴(Tang等,2019)的研究,我们采用Hit@k(k = 1, 3, 5)作为评估指标,对所有可能的话题进行排序。
Baselines.
我们考虑以下基线模型进行性能比较:(1)PMI通过计算与最后一个话题的点互信息进行排序。(2)MGCG(Liu等,2020)是最近提出的基于多类型GRU(使用特殊GRU编码用户画像)的对话推荐系统模型。(3)Conversation/Topic/Profile-BERT分别利用对话/话题/画像-BERT对历史话语/话题/用户画像进行编码以预测下一个话题。(4)Ours w/o target是我们提出的模型的消融模型,从输入中移除目标话题。
Result and Analysis.
表3展示了不同方法在话题预测任务中的表现。可以看出,PMI表现不佳,因为它无法考虑目标话题。其次,Conversation/Topic-BERT的表现优于MGCG。这表明预训练语言模型BERT特别适合捕捉话题语义。在基于BERT的模型中,ProfileBERT表现较差,因为在此任务中历史话语和话题更为重要。此外,我们的模型优于所有基线模型,因为它联合利用了由不同BERT模型编码的历史话语、话题和用户画像。最后,从BERT模型的输入中移除目标话题后,性能显著下降,表明目标话题的重要性。

5.3 Evaluation on Response Generation
最后,我们评估了我们方法在回应生成任务中的表现。借鉴(Chen等,2019;Qiu等,2019;Tao等,2018a)的研究,我们采用困惑度(PPL)和BLEU-1,2,3来评估生成回应与真实回应之间的相关性,并采用Distinct-1,2来评估生成话语的信息量。此外,我们邀请人工标注者对生成结果的相关性、流畅性和信息量进行评分,评分范围为[0, 2]。
Baselines.
我们考虑以下基线模型进行性能比较:(1)ReDial(Li等,2018)采用分层RNN进行回应生成。(2)KBRD(Chen等,2019)应用Transformer并基于知识图谱增强词权重建模。(3)Transformer(Vaswani等,2017)应用基于Transformer的编码器-解码器框架生成适当的回应。(4)GPT-2(Radford等,2019)是一种预训练文本生成模型,并在TG-ReDial数据集上进行了微调。
Result and Analysis.
表4展示了不同方法在回应生成任务中的表现。首先观察到ReDial在我们的数据集上表现不佳。一个主要原因是ReDial采用分层RNN进行回应生成,这不适合编码长话语(回想一下,我们数据集中的话语更长且信息量更大)。其次,Transformer在大多数指标上优于KBRD,因为KBRD利用知识图谱信息提升实体和项目的预测概率,这可能对文本生成产生不利影响。此外,Transformer、GPT-2和我们的模型在BLEU分数上表现相似。对于PPL、Distinct和人工评估,Transformer表现最差,而我们的模型表现非常好。实际上,BLEU可能不适合评估对话推荐系统(Tao等,2018b),因为它更容易受到停用词等无意义词的影响。最后,我们的模型在大多数情况下优于所有基线模型,因为它可以利用预测的话题或项目来提升生成文本的质量。

6 Conclusion
我们为对话推荐系统引入了一个高质量的数据集TG-ReDial,该数据集基于真实用户数据通过人工标注构建。基于TG-ReDial,我们提出了话题引导的对话推荐任务及其解决方案。大量实验证明了所提出方法在三个子任务中的有效性。目前,TG-ReDial数据集的潜力尚未完全挖掘。它可以作为更多任务的测试平台,例如个性化闲聊(Zhang等,2018a)、目标引导对话(Tang等,2019)和序列推荐(Zhou等,2020a)。作为未来工作,我们将在TG-ReDial数据集上研究这些任务。此外,我们还将考虑如何构建更有效的话题引导对话推荐方法。




